
编辑:编辑部 HYZ
【新智元导读】LLM统一了语言生成任务,图像生成可以吗?就在刚刚,智源推出了全新扩散模型架构OmniGen,单个模型就能生成图像,彻底告别繁琐工作流!
大语言模型(LLM)的出现统一了语言生成任务,并彻底改变了人机交互。
然而,在图像生成领域,能够在单一框架内处理各种任务的统一模型在很大程度上仍未得到探索。
近日,智源推出了新的扩散模型架构OmniGen,一种新的用于统一图像生成的多模态模型。

论文地址:https://arxiv.org/pdf/2409.11340
代码仓库:https://github.com/VectorSpaceLab/OmniGen
Demo: https://huggingface.co/spaces/Shitao/OmniGen
OmniGen具有以下特点:
统一性:OmniGen天然地支持各种图像生成任务,例如文生图、图像编辑、主题驱动生成和视觉条件生成等。此外,OmniGen可以处理经典的计算机视觉任务,将其转换为图像生成任务。
简单性:OmniGen的架构高度简化。此外,与现有模型相比,它更加用户友好,可以通过指令完成复杂的任务,而不需要冗长的处理步骤和额外的模块(如ControlNet或IP-Adapter),从而大大简化了工作流程。
知识迁移:受益于统一格式的学习,OmniGen有效地跨不同任务迁移知识,应对未见过的任务和领域,并展示新颖的功能。研究人员还探讨了模型的推理能力和思维链机制的在图像生成领域的潜在应用。

基于OmniGen的通用能力,可实施更灵活的图像生成,以上展示一个简单 Pipeline:文本生成图像,编辑生成图像的部分元素,根据生成图像的人体姿态生成重绘图像,从另一图像中提取所需对象与新图像融合
介绍
近年来,许多文生图模型在生成式AI的浪潮中脱颖而出。然而,这些出色的专有模型仅能基于文本生成图像。当用户产生更灵活、复杂、精细等的图像生成需求时,往往需要额外的插件和操作。
例如,若想参考任一姿态生成图像,常规方法是:用姿态检测器从参考图像中估计姿态作为条件输入,并加载对应的Controlnet插件,最后提取条件输入的特征馈入扩散模型生成图像。
此外,若想基于合照中的特定人物生成新图像,流程更加繁琐,需要裁剪图像以确保结果图像仅包含目标人物。而诸如InstandID等方法还需使用额外的人脸检测器提取面部信息,并用面部编码器提取特征以输入模型。
值得注意的是,各种不同的生成任务甚至还需更多不同的插件和操作,如此复杂、琐碎而冗长的工作流极大地增加了训练和应用的成本。
然而,即便如此繁琐,有时也仍难以满足一般的图像生成的需求,例如基于指定多张照片中的实体生成新图像。
相反,在文本生成领域,以ChatGPT为代表的模型可通过人类指令直接处理各种文本任务。
那么,在图像生成领域,能否通过单个支持多种输入且耦合多项能力的模型,基于用户指令完成各种生成任务,而无需各种繁杂的流程吗?
为解决这一挑战性问题,智源发布了统一图像生成模型OmniGen。
OmniGen模型具有良好的简洁性和易用性,集成了多种基础图像生成任务,包括但不限于:文生图、图像编辑、角色一致性生成、基于视觉条件的生成等。OmniGen支持基于任意多模态的文图指令完成任务,而无需任何其他额外插件和操作。
能力
OmniGen集多项能力于一体,包括但不限于:
文本到图像生成(Text to Image Generation)
指代表达生成(Referring Expression Generation)
通用图像条件生成(General Image Conditional Generation)
图像编辑(Image Edit)
经典计算机视觉任务:图像去噪、边缘检测、姿态估计等
在经历了强劲的上涨之后,日本股市近几个月来一直落后于全球同行,原因是国内经济增长乏力、企业业绩预期令人失望,以及市场担心日本央行提高借贷成本的后果。保证金买家实际上是从经纪商那里借钱购买股票,通常使用高杠杆,如果市场走弱,投资者可能需要平仓,从而导致进一步抛售。
一定的上下文学习能力(In-context Learning)
以下简要展示部分能力效果:
1. 文本到图像生成

2. 指代表达生成
OmniGen具备类似InstandID、Pulid等模型生成角色一致性图像等能力,即:输入具有单个对象的图像,理解并遵循指令,输出基于该对象的新图像。
同时,OmniGen具有更高阶的能力:指代表达生成能力,我们把这种能力定义为能够从包含多个对象的图像中,识别指令所指代的对象并生成新的图像。
例如,OmniGen可根据指令直接从多人图像中定位目标对象,并生成遵循指令的新图像,而无需任何额外的模块和操作:
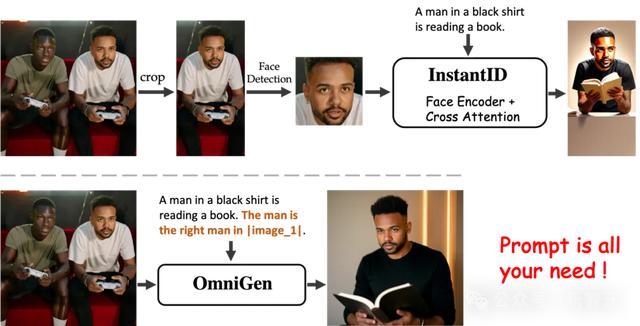
更多样例:

3. 通用图像条件生成
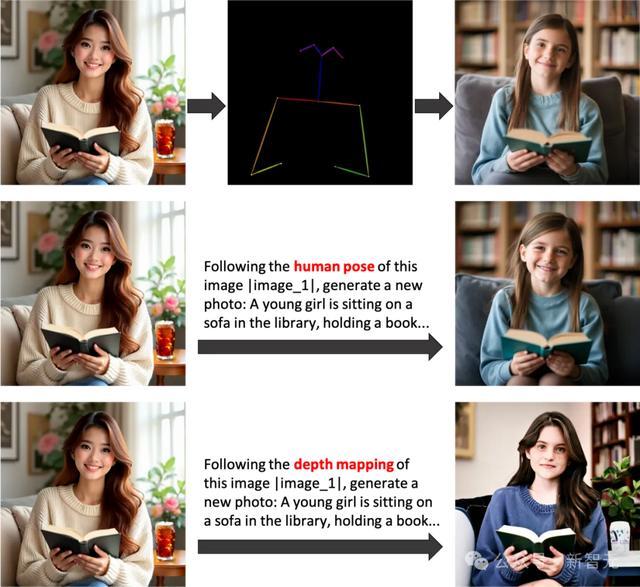
OmniGen不仅支持类似ControlNet根据特定显式条件生成图像的能力,还同时具备处理经典计算机视觉任务的能力(如人体姿态估计、深度估计等)。
因此,OmniGen可凭借单个模型完成整个ControlNet流程:直接使用OmniGen对原图提取视觉条件,并基于所提取的条件生成图像,无需额外处理器。
同时,OmniGen还能更进一步简化中间流程,一步出图:直接输入原图,输入指令「Following the human pose (or depth mapping) of this image, generate a new image: ...」,就可根据输入图像的人体姿态或深度图关系生成新图像。
4. 图像编辑
OmniGen具备良好的图像编辑能力,并且可以在一次运行中同时执行多条编辑指令,例如:

5. 更多能力
OmniGen具备潜在的推理能力,可以处理对模型理解和推断能力具有一定要求的非显式查询指令。
例如,要求模型删除图中能装水的物品,则模型能够理解和推断出指令涉及的图中物体并删除:

另一方面,OmniGen具有一定程度的上下文学习能力,可根据参考样例对图像进行处理。
例如,输入一个分割皇后象棋的输入-输出配对样例(Example),模型能识别并分割新输入图像中对应的物体:

思维链(Chain-of-Thought, CoT)方法将任务分解为多个步骤,并按顺序求解每个步骤以获得准确的最终答案,从而显著提高了LLM的性能。
那么,是否可以将类似的替代方案应用于图像生成呢?受人类绘画的基本方式的启发,研究人员希望模仿一步一步的绘画过程,从空白画布上迭代地生成图像。
研究人员进行了初步的探索,微调后模型能够模拟人类行为一步步的生成图片,进一步的优化留给以后的研究。

OmniGen的能力包括但不限于以上内容,还包括基本的图像去噪、边缘提取等能力。模型权重和代码已开源,用户可以自行探索更多OmniGen的能力。
模型
OmniGen的核心设计原则是:简洁和有效。
因此,研究人员最大程度舍弃了各种额外模块。OmniGen的基本架构为:一个 Transformer 模型和一个VAE模块,共3.8B参数。
其中,Transformer继承于Phi3-mini模型,图像内部改用双向注意力(Bidirectional Attention) 以契合图像数据特性。
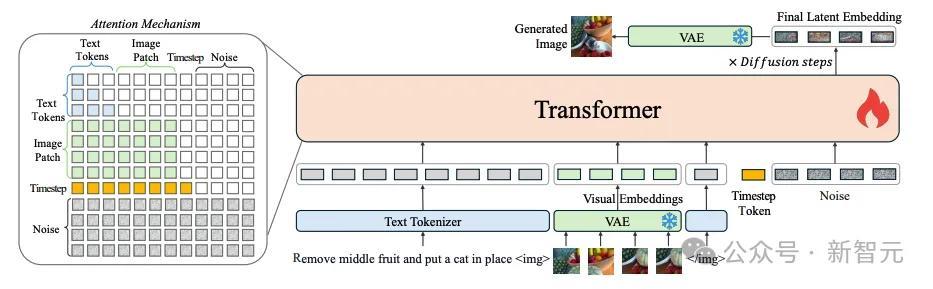
整体架构
为实现强大的通用和泛化能力,研究人员需要基于大规模和多样化的数据集训练模型。然而,在图像生成领域,尚无一个可用的通用数据集。
为此,研究人员构建了首个大规模且多样化的统一图像生成数据集X2I,意为 「Anything to Image」。
其中,不同任务的数据格式被重新组织和统一,以便于管理和使用。
X2I数据集包含约1亿图像,未来经审查等流程后将开源,旨在进一步推动通用图像生成领域的发展。

X2I数据集的一些示例
小结与展望
总之,OmniGen的统一图像生成范式,不但有助于执行各种下游任务,而且有利于组合各种能力满足更通用的需求。
当前,OmniGen的报告、权重和代码等已开源,欢迎社区共同参与对OmniGen潜在能力的发掘、基本性能的提升和广泛应用的探索。
OmniGen模型是对统一图像生成的初步尝试,还有很大的提升空间。未来,智源将进一步改进模型基本能力,拓展更多有趣的功能。
同时,微调代码已发布股票杠杆叠加,用户可简单对其进行微调,由于OmniGen的输入形式非常多样,用户可自行定义各式各样的微调任务,赋予模型更多有意思的能力。